


Building Smarter Fee Schedule Processing With AI in RCM
Fee schedule updates present as basic administrative work, yet in Dental RCM they consistently require substantial processing time and effort. Each time a new PPO contract is signed, teams receive long PDFs full of CDT codes and corresponding fees. Someone has to extract only the relevant codes and update them in the practice management system.
This operational bottleneck became the starting point of our shift toward applying AI document processing in dental workflows. The goal was straightforward: build a system that can interpret fee schedules reliably, handle variation across carriers, and deliver results faster than manual processing ever could.
Why We Decided to Build This System
At first, it looked like a standard AI in RCM workflow. Azure Document Intelligence could read PDFs. Large models could reason about structure. Together, they should automate fee extraction.
That assumption held up until we tested real carrier documents.
Fee schedules came in every shape and format:
- Clean digital PDFs
- Low-resolution, fax-style scans
- Tables without borders
- Tables placed side-by-side
- Paragraph-style fee lists
- Missing headers
- Multiple fee types in the same document
- OCR distortions where "D0120" became "D01Q0"
One carrier could send a perfectly structured layout, while another could send a heavily compressed scan with inconsistent column spacing. No single model could interpret every format reliably.
So the solution couldn’t be a single model.
It needed to be a pipeline layered, adaptive, and capable of escalating to more advanced reasoning only when necessary.
That design decision shaped our AI revenue cycle management architecture.
Where Traditional OCR Breaks Down
OCR tools assume structured tables and consistent spacing. Fee schedules rarely follow that pattern.
One of the biggest early failures came from Azure Document Intelligence merging multiple side-by-side tables into a single multi-column result. A page with three simple two-column tables became a single twelve-column structure with no logical separation.
At that point, the direction was clear:
A simple "upload → parse table" approach would never survive real-world dental documents.
We needed a system that adapts to the document, not the other way around.
The Six-Stage Pipeline That Made It Work

We built a pipeline aligned to real production conditions. It always attempts rule-based logic first. Only when rules fail does it escalate to document understanding AI, and only when that fails does it escalate again.
This sequencing keeps accuracy high and cost predictable.
Stage 0: Code Density Detection
Before processing the document, the system evaluates its complexity.
A visual model estimates CDT code density in a representative page. Dense schedules are split into horizontal snippets. Sparse layouts are processed as-is. A slight overlap prevents rows from being cut mid-extraction.
This small adjustment dramatically improved layout interpretation accuracy.
Stage 1: PDF Splitting & Azure DI Analysis
Each snippet becomes an independent page processed by Azure DI. The system extracts:
- Structured tables (when detected)
- Line-level bounding-box text (for unstructured layouts)
If DI identifies tables correctly, they move forward. If not, the system reconstructs the structure using coordinate clustering and regex-based pattern recognition.
Both DI-derived and reconstructed tables feed downstream nothing is discarded.
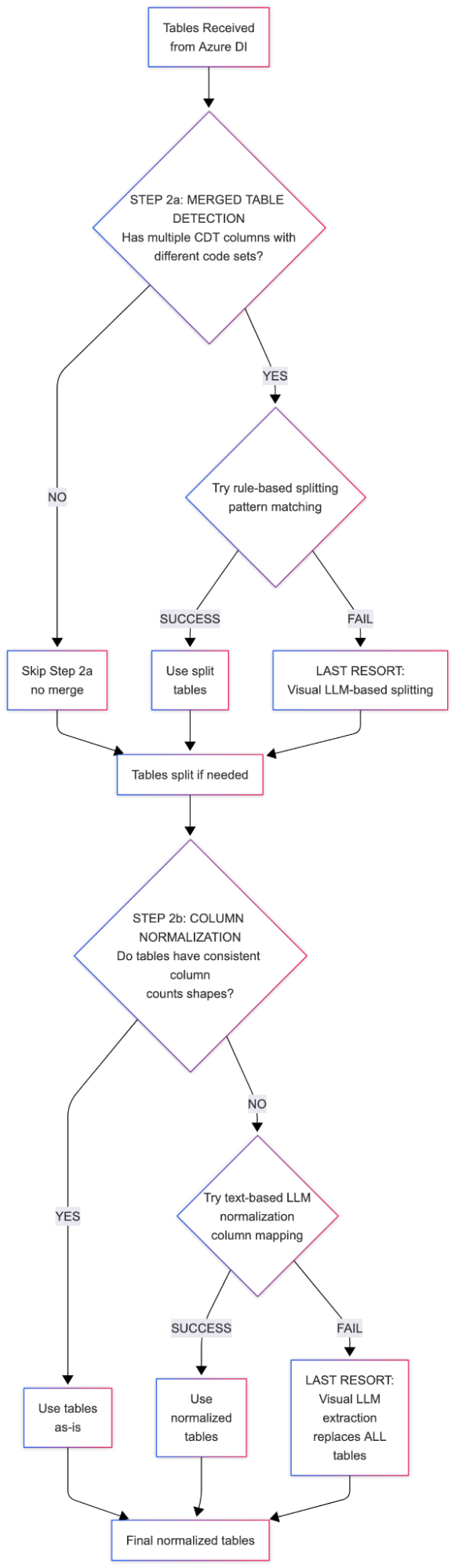
Stage 2: Structure Normalization
This is where structural inconsistencies are resolved.
2a. Splitting Merged Tables
Merged tables are detected by identifying multiple CDT-like column patterns. Rule-based splitting handles most cases. When the layout is irregular, a visual model references the snippet and reconstructs true boundaries.
2b. Normalizing Column Counts
Table structures vary widely. The system identifies the dominant structure and normalizes everything to match. If text-based logic fails, the pipeline escalates to visual extraction.
This cascaded fallback approach is key to resilience.
Stage 3: Identifying CDT and Fee Columns
Once structure stabilizes, the system identifies the correct columns.
3a. Rule-Based Detection
Pattern matching, numeric density, and header evaluation allow the system to determine CDT and fee columns quickly in most documents.

3b. LLM Adjudication
Escalation happens only when structure remains ambiguous:
- Multiple similar CDT candidates
- Multiple fee columns
- Missing headers
- Conflicting numeric patterns
- Visually ambiguous layouts
The model reviews the snippet and confirms column roles. If multiple fee types exist (UCR, in-network, out-of-network), it returns all valid possibilities, and the user chooses which set to extract.
Stage 4: Extracting Clean CDT–Fee Pairs
Once structure and column roles are confirmed, extraction becomes systematic.
The system:
- Sorts rows using bounding-box coordinates
- Merges duplicate representations
- Maps CDT codes to the correct fee column selected by the user
The final output is a clean, structured fee schedule ready for import.
The Debugging Nightmare
The pipeline worked, but early debugging was difficult. A single document could trigger:
- Rule-based logic
- Text-based fallback
- Visual adjudication
- Column reasoning
- Re-extraction
There was no visibility into which path the system took or why. If an error occurred, reproducing it required trial-and-error re-processing.
We needed traceability.
Building Observability Into the Pipeline
We added a diagnostics system that logs every decision, fallback and cost event. Every processed PDF now generates a detailed execution record.
Example:

With observability, debugging shifted from guesswork to inspection. It also revealed patterns, such as:
- Scanned files almost always trigger visual extraction
- Certain carriers consistently break rule-based logic
- Some layouts repeatedly merge tables
Those patterns became new rules incrementally improving the system.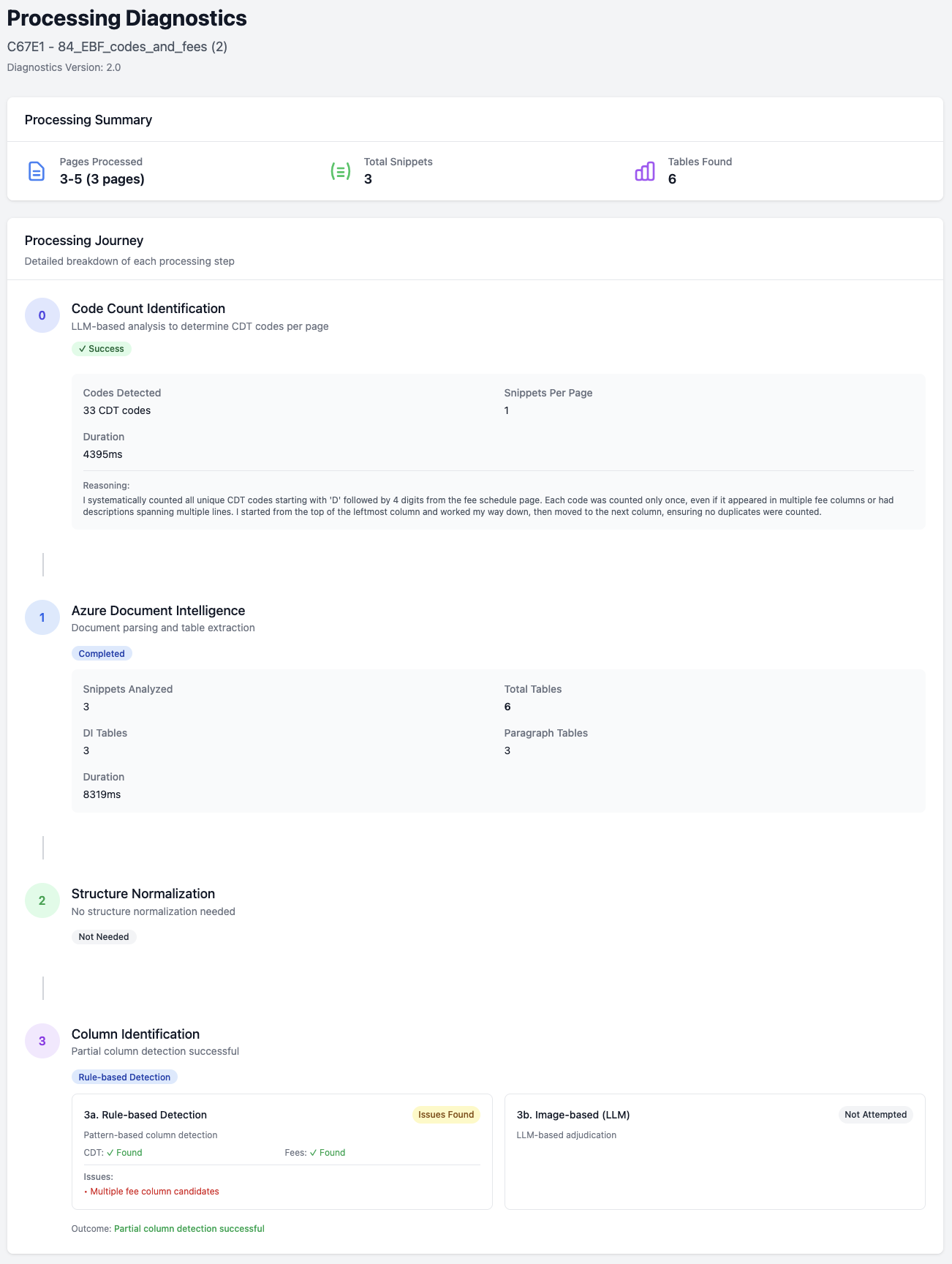
The Hybrid AI Philosophy
From the beginning, we made one core architectural decision:
Rules first. AI only when necessary.
Rule-based logic ensures:
- Speed
- Low cost
- Deterministic output
- Testability
- Version-safe behavior
AI provides:
- Visual reasoning
- Layout interpretation
- Flexibility across unknown formats
A rule-only system would break on layout variation.
An AI-only system would be expensive and unpredictable at scale.
The hybrid model delivers reliability, control, and adaptability.
The Real Impact on RCM Teams
Today, the workflow looks completely different.
- Agents upload a PDF and continue working.
- The system processes the schedule automatically.
- QC reviews exceptions, not entire documents.
- Accuracy improves release after release.
- Patterns discovered in production become new automation rules.
- AI usage becomes precise and intentional only where it adds value.
This is what mature AI in dentistry looks like: not a single model attempting to automate everything, but a layered infrastructure designed for real documents, real scale, and continuous improvement.
Where This Goes Next
Fee schedule extraction used to be one of the slowest steps in Dental RCM. By combining deterministic logic with AI document processing and layered escalation using document understanding AI, we now have a system that adapts, learns and improves with every processed document.
It isn't theoretical and it isn’t one model.
It's a scalable, observable, rule-first workflow shaped by real production data and built for operational accuracy, speed and consistency.